Los contenedores existen desde hace muchos años, Docker no ha inventado nada en ese sentido, o casi nada, pero no hay que quitarles mérito, están en el momento adecuado y aportan las características y herramientas concretas que se necesitan en la actualidad, donde la portabilidad, escalabilidad, alta disponibilidad y los microservicios en aplicaciones distribuidas son cada vez más utilizados, y no sólo eso, sino que también son mejor entendidos por la comunidad de desarrolladores y administradores de sistemas. Cada vez se desarrollan menos aplicaciones monolíticas y más basadas en módulos o en microservicios, que permiten un desarrollo más ágil, rápido y a la vez portable. Empresas de sobra conocidas como Netflix, Spotify o Google e infinidad de Start ups usan arquitecturas basadas en microservicios en muchos de los servicios que ofrecen.
Te estarás preguntando ¿Y no es más o menos lo mismo que hacer un chroot de una aplicación? Sería como comparar una rueda con un coche. El concepto de chroot es similar ya que se trata de aislar una aplicación, pero Docker va mucho más allá, sería un chroot con esteroides, muchos esteroides. Por ejemplo, puede limitar y controlar los recursos a los que accede la aplicación en el contenedor, generalmente usan su propio sistema de archivos como UnionFS o variantes como AUFS, btrfs, vfs, Overlayfs o Device Mapper que básicamente son sistemas de ficheros en capas. La forma de controlar los recursos y capacidades que hereda del host es mediante namespaces y cgroups de Linux. Esas opciones de Linux no son nuevas en absoluto, pero Docker lo hace fácil y el ecosistema que hay alrededor lo ha hecho tan utilizado.
Adicionalmente, la flexibilidad, comodidad y ahorro de recursos de un contenedor es mayor a la que aporta una máquina virtual o un servidor físico, esto es así en muchos casos de uso, no en todos. Por ejemplo, tres servidores web para un cluster con Nginx en una VM con una instalación de Linux CentOS mínima ocuparía unos 400MB, multiplicado por 3 máquinas sería total de uso en disco de 1,2 GB, con contenedores serían 400MB las mismas 3 máquinas corriendo ya que usa la misma imagen para múltiples contenedores. Eso es sólo por destacar una característica interesante a nivel de recursos. Otro uso muy común de Docker es la portabilidad de aplicaciones, imagina una aplicación que solo funciona con Python 3.4 y hacerla funcionar en un sistema Linux con Python 2.x es complicado, piensa en lo que puede suponer en un sistema en producción actualizar Python, con contenedores sería casi automático, descargar la imagen del contenedor y ejecutar la aplicación de turno.
Pero un contenedor no es para todo, ni hay que volverse loco “dockerizando” cualquier cosa, aunque no es este el sitio para esa reflexión. Al cambiar la forma de desarrollar, desplegar y mantener aplicaciones, también cambia en cierto modo la forma de securizar estos nuevos actores.
1. Recomendaciones a nivel de host
1.1. Crear una partición separada para los contenedores
1.2. Usar un Kernel de Linux actualizado
1.3. No usar herramientas de desarrollo en producción
1.4. Securizar el sistema anfitrión
1.5. Borrar todos los servicios no esenciales en el sistema anfitrión
1.6. Mantener Docker actualizado
1.7. Permitir solo a los usuarios autorizados controlar el demonio Docker
1.8. Auditar el demonio Docker (auditd)
1.9. Auditar el fichero o directorio de Docker – /var/lib/docker
1.10. Auditar el fichero o directorio de Docker – /etc/docker
1.11. Auditar el fichero o directorio de Docker – docker-registry.service
1.12. Auditar el fichero o directorio de Docker – docker.service
1.13. Auditar el fichero o directorio de Docker – /var/run/docker.sock
1.14. Auditar el fichero o directorio de Docker – /etc/sysconfig/docker
1.15. Auditar el fichero o directorio de Docker – /etc/sysconfig/docker-network
1.16. Auditar el fichero o directorio de Docker – /etc/sysconfig/docker-registry
1.17. Auditar el fichero o directorio de Docker – /etc/sysconfig/docker-storage
1.18. Auditar el fichero o directorio de Docker – /etc/default/docker
2. Recomendaciones a nivel de Docker Engine (daemon)
2.1 No usar el driver obsoleto de ejecución de lxc
2.2 Restringir el tráfico de red entre contenedores
2.3 Configurar el nivel de logging deseado
2.4 Permitir a Docker hacer cambios en iptables
2.5 No usar registros inseguros (sin TLS)
2.6 Configurar un registro espejo local
2.7 No usar aufs como driver de almacenamiento
2.8 No arrancar Docker para escuchar a una IP/Port o Unix socket diferente
2.9 Configurar autenticación TLS para el daemon de Docker
2.10 Configurar el ulimit por defecto de forma apropiada

3. Recomendaciones a nivel de configuración de Docker
3.1 Verificar que los permisos del archivo docker.service están como root:root
3.2 Verificar que los permisos del archivo docker.service están en 644 o más restringidos
3.3 Verificar que los permisos del archivo docker-registry.service están como root:root
3.4 Verificar que los permisos del archivo docker-registry.service están en 644 o más restringidos
3.5 Verificar que los permisos del archivo docker.socket están como root:root
3.6 Verificar que los permisos del archivo docker.socket están en 644 o más restringidos
3.7  Verificar que los permisos del archivo de entorno Docker (/etc/sysconfig/docker o /etc/default/docker) están como root:root
3.8 Verificar que los permisos del archivo de entorno Docker (/etc/sysconfig/docker o /etc/default/docker) están en 644 o más restringidos
3.9 Verificar que los permisos del archivo /etc/sysconfig/docker-network (si se usa systemd) están como root:root
3.10 Verificar que los permisos del archivo /etc/sysconfig/docker-network están en 644 o más restringidos
3.11  Verificar que los permisos del archivo /etc/sysconfig/docker-registry (si se usa systemd) están como root:root
3.12 Verificar que los permisos del archivo /etc/sysconfig/docker-registry (si se usa systemd) están en 644 o más restringidos
3.13 Verificar que los permisos del archivo /etc/sysconfig/docker-storage (si se usa systemd) están como root:root
3.14 Verificar que los permisos del archivo /etc/sysconfig/docker-storage (si se usa systemd) están en 644 o más restringidos
3.15 Verificar que los permisos del directorio /etc/docker están como root:root
3.16 Verificar que los permisos del directorio /etc/docker están en 755 o más restrictivos
3.17 Verificar que los permisos del certificado del registry están como root:root
3.18 Verificar que los permisos del certificado del registry están en 444 o más restringidos
3.19 Verificar que los permisos del certificado TLS CA están como root:root
3.20 Verificar que los permisos del certificado TLS CA están en 444 o más restringidos
3.21 Verificar que los permisos del certificado del servidor Docker están como root:root
3.22 Verificar que los permisos del certificado del servidor Docker están en 444 o más restringidos
3.23 Verificar que los permisos del archivo de clave del certificado del servidor Docker están como root:root
3.24 Verificar que los permisos del archivo de clave del certificado del servidor Docker están en 400
3.25 Verificar que los permisos del archivo de socket de Docker están como root:docker
3.26 Verificar que los permisos del archivo de socket de Docker están en 660 o más restringidos
4 Imágenes de Contenedores y Dockerfiles
4.1 Crean un usuario para el contenedor
4.2 Usar imágenes de confianza para los contenedores
4.3 No instalar paquetes innecesarios en el contenedor
4.4 Regenerar las imágenes si es necesario con parches de seguridad
5 Runtime del contenedor
5.1 Verificar el perfil de AppArmor (Debian o Ubuntu)
5.2 Verificar las opciones de seguridad de SELinux (RedHat, CentOS o Fedora)
5.3 Verificar que los contenedores esten ejecutando un solo proceso principal
5.4 Restringir las Linux Kernel Capabilities dentro de los contenedores
5.5 No usar contenedores con privilegios
5.6 No montar directorios sensibles del anfitrión en los contenedores
5.7 No ejecutar ssh dentro de los contenedores
5.8 No mapear puertos privilegiados dentro de los contenedores
5.9 Abrir solo los puertos necesarios en un contenedor
5.10 No usar el modo “host network” en un contenedor
5.11 Limitar el uso de memoria por contenedor
5.12 Configurar la prioridad de uso de CPU apropiadamente
5.13 Montar el sistema de ficheros raíz de un contenedor como solo lectura
5.14 Limitar el tráfico entrante al contenedor mediante una interfaz específica del anfitrión
5.15 Configurar la política de reinicio ‘on-failure’ de un contenedor a 5
5.16 No compartir PID de procesos del anfitrión con contenedores
5.17 No compartir IPC del anfitrión con contenedores
5.18 No exponer directamente dispositivos del anfitrión en contenedores
5.19 Sobre-escribir el ulimit por defecto en tiempo de ejecución solo si es necesario
6 Operaciones de Seguridad en Docker
6.1 Realizar auditorías de seguridad tanto en el anfitrión como en los contenedores de forma regular
6.2 Monitorizar el uso, rendimiento y métricas de los contenedores
6.3 Endpoint protection platform (EPP) para contenedores (si las hubiese)
6.4 Hacer Backup de los datos del contenedor
6.5 Usar un servicio centralizado y remoto para recolección de logs
6.6 Evita almacenar imágenes obsoletas, sin etiquetar correctamente o de forma masiva.
6.7 Evita almacenar contenedores obsoletos, sin etiquetar correctamente o de forma masiva.


 SCAP (Security Content Automation Protocol)
SCAP (Security Content Automation Protocol)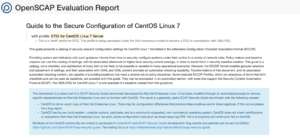
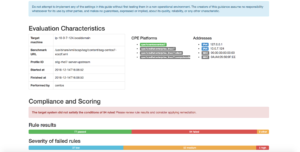
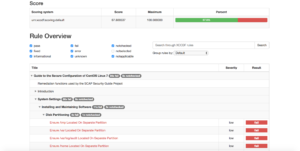
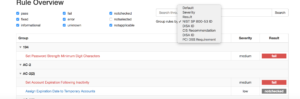
 In order to give back to the Open Source community what we take from it (actually from the
In order to give back to the Open Source community what we take from it (actually from the  Now, with this provided CloudFormation template you can deploy SecurityMonkey pretty much production ready in a couple of minutes.
Now, with this provided CloudFormation template you can deploy SecurityMonkey pretty much production ready in a couple of minutes.
