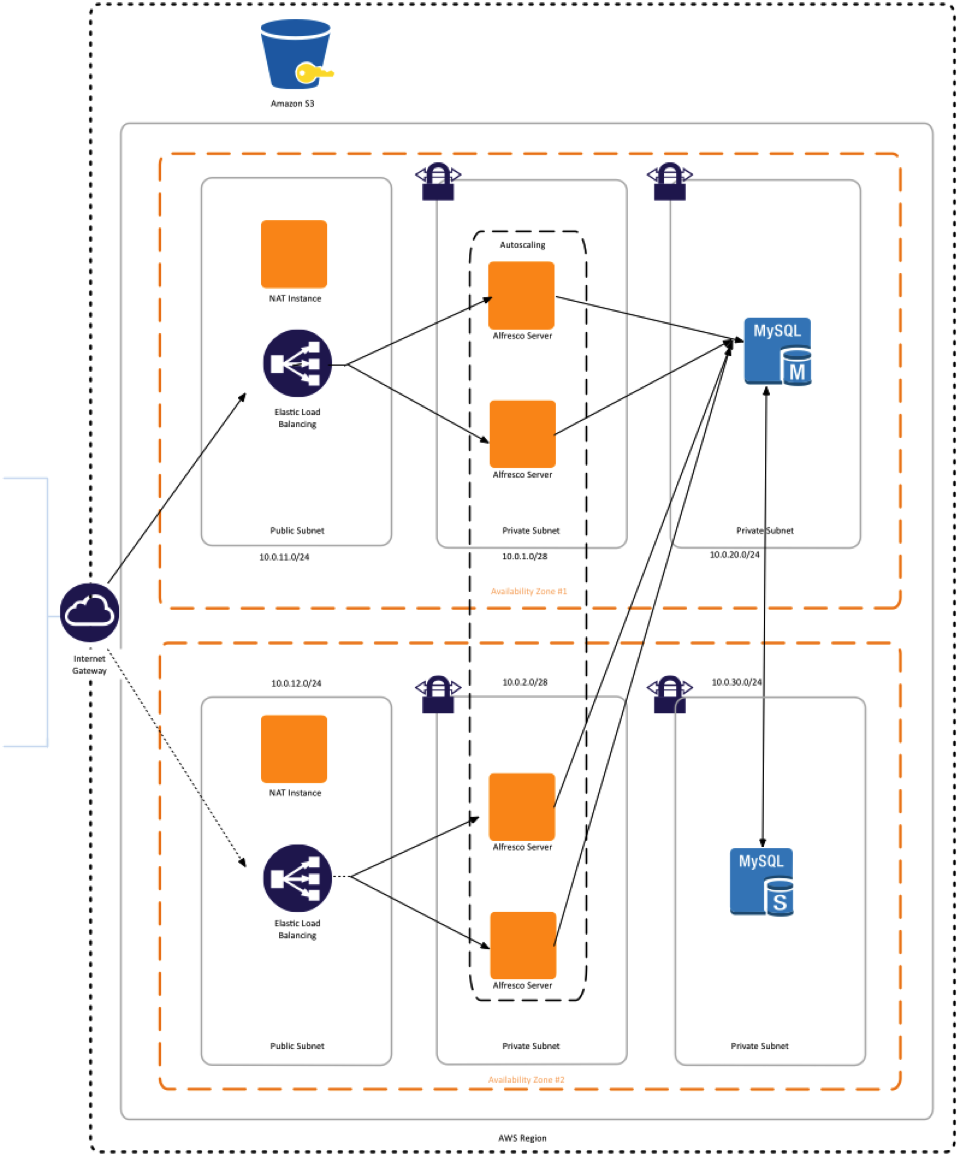
The main requirement on the shared storage is being able to cross-mount the storage between the Alfresco servers. Whether this is done via an NAS or SAN is partly a decision around which technology your organization’s IT department can best support. Faster storage will have positive implications on the performance of the system, with Alfresco recommending throughput at 200 MB/sec.
NAS allows us to mount the content store via NFS or CIFS on all Alfresco servers, and they are able to read/write the same file system at the same time. The only real requirement is that the OS on which Alfresco is installed supports NFS (which is any Linux box actually). NFS tends to be cheaper and easier, but is not the fastest option. It is typically sufficient, though.
SAN is typically faster and more reliable, but obviously more expensive and complex (dedicated hardware and configuration requirements). In order to read/write from all Alfresco servers from/to the SAN, special file system types are necessary. For Red Hat, we use GFS2, other Linux flavors use OCFS or many others.
You are maybe thinking what happen in case of having multiple Alfresco servers writing to the same LUN could result in corruption (especially in header files), so it sounds like NAS (NFS/CIFS) would take care of that issue, however, if using a SAN, the filesystem must be managed properly to allow for read/write from multiple servers. For the Alfresco stand point, you don’t have to take care of that in both SAN or NAS approaches because Alfresco manages the I/O such that no collisions or corruption occur.
Note: If using a SAN, ensure the file system is managed properly to allow for read/write from multiple servers.
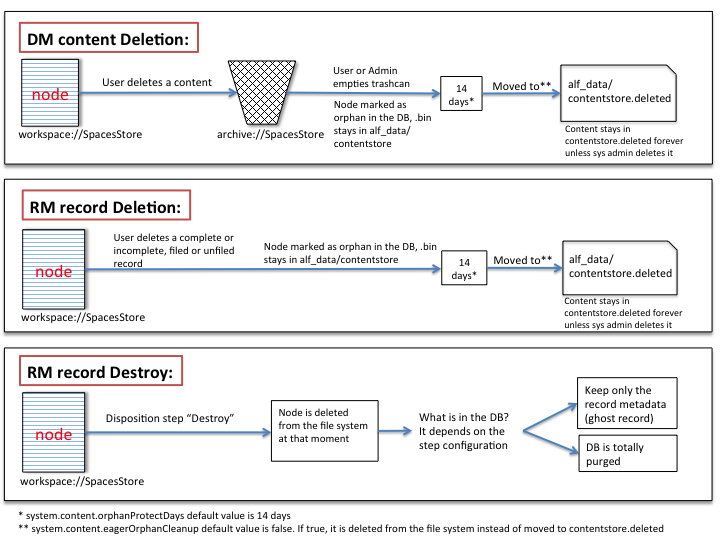
I also wanted to share this presentation I did internally some time ago but I think it would be useful.